¶ What is Object Detection ?
Object detection is a computer vision technique that involves identifying and locating objects within an image or video. It combines classification and localization to not only determine what an object is but also where it is within a given frame.
¶ Applications of Object Detection
Object detection has widespread applications across multiple domains:
- Surveillance: Identifying suspicious behavior or unauthorized access in real time.
- Autonomous Driving: Recognizing other vehicles, pedestrians, traffic signs, and obstacles to ensure safe navigation.
- Medical Imaging: Assisting in the detection of anomalies such as tumors in X-rays, MRIs, or CT scans.
- Retail: Tracking inventory, analyzing customer behavior, or even enhancing security by detecting unusual activity.
Object detection models play a crucial role in automating processes and providing valuable insights across industries. Now, let's look at the key concepts that form the foundation of object detection.

¶ Essential Terminology: Key Concepts in Object Detection
To work effectively with object detection, it’s important to understand several core concepts. Here’s an overview of the primary terminology:
¶ Bounding Boxes
Bounding boxes are rectangular frames drawn around detected objects. They define the spatial location and size of the object within an image. Bounding boxes are typically represented by coordinates, either as:
- (xmin, ymin, xmax, ymax), which identifies the box’s corners.
- (xcenter, ycenter, width, height), which centers the box around a point.
Purpose: The primary purpose of bounding boxes is to mark the position of each detected object.
Limitations: Bounding boxes often encompass extra background pixels, which may lead to inaccuracies for objects with irregular shapes.
¶ Intersection over Union (IoU)
Intersection over Union, or IoU, is a metric for assessing the accuracy of detected bounding boxes. It measures the overlap between the predicted box and the ground truth box:
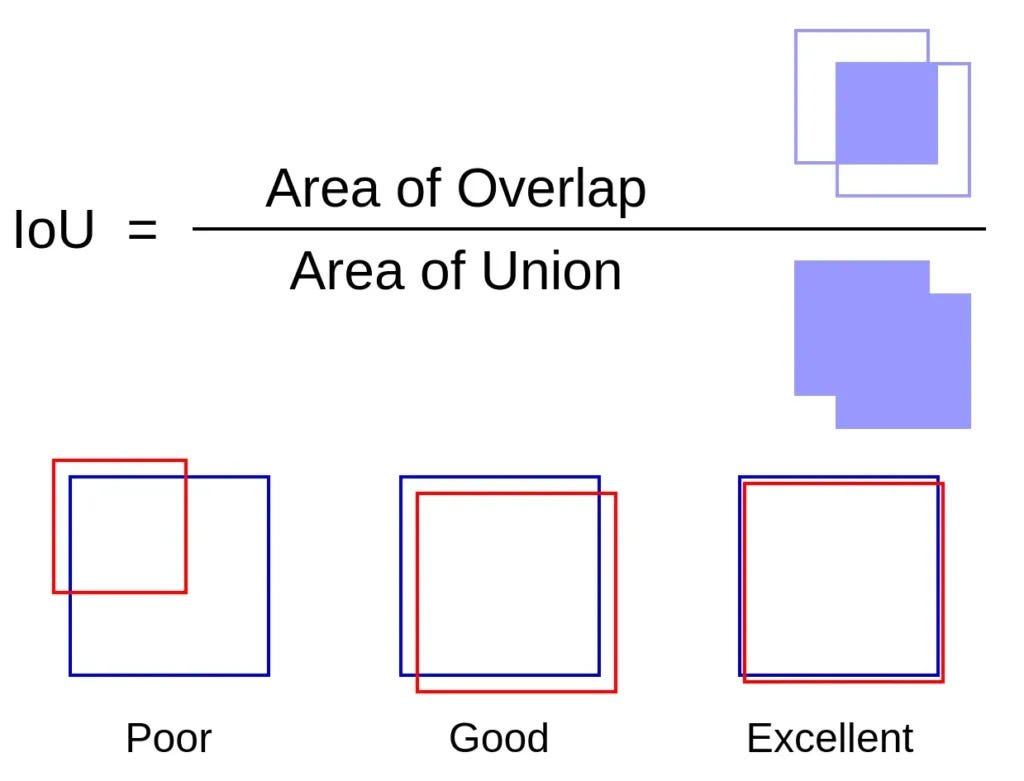
- High IoU: Indicates close alignment with the actual object, signaling an accurate prediction.
- Low IoU: Suggests misalignment and potential error in the prediction.
IoU is commonly used as a threshold (e.g., IoU > 0.5) to determine if a detected box qualifies as accurate.
¶ Confidence Scores
Confidence scores indicate the model’s certainty about the presence of an object within a detected bounding box, typically represented as a value between 0 and 1:
- High Scores: Show that the model is confident in its prediction, reducing the risk of false positives.
- Low Scores: Reveal uncertainty, often leading to the box being discarded to avoid incorrect classifications.
Confidence scores help balance the trade-off between precision and recall, with low-confidence boxes generally filtered out to maintain reliability.
¶ Classes
Classes define the type of object detected, such as "person," "car," or "cat." Object detection models often support:
- Single-Class Detection: For detecting a specific object of interest.
- Multi-Class Detection: For detecting multiple types of objects in the same image, essential for applications like autonomous driving.
¶ 5. Anchor Boxes
Anchor boxes are predefined bounding boxes of different sizes and aspect ratios, used to detect objects of varying scales. During detection, anchor boxes are placed across the image and adjusted by the model to fit objects.
- Advantages: Enable the model to detect small, medium, and large objects within the same image.
- Limitations: May increase computational load if too many anchor boxes are used.
Anchor boxes help the model address scale variance in objects, which is crucial for tasks like detecting pedestrians or vehicles of different sizes.
¶ 6. Non-Maximum Suppression (NMS)
Non-Maximum Suppression is a post-processing technique used to eliminate redundant bounding boxes for the same object. It works by selecting the box with the highest confidence score and discarding other overlapping boxes if their IoU with the selected box exceeds a given threshold.
The steps in NMS are as follows:
- Rank all detected boxes by confidence score.
- Select the box with the highest score and suppress all overlapping boxes with an IoU greater than a set threshold.
- Repeat until only the best boxes remain.
This process reduces duplicate detections and ensures that each object is represented by only one bounding box.
¶ 7. Precision, Recall, and F1 Score
To evaluate the performance of an object detection model, we often use metrics such as Precision, Recall, and F1 Score.
Let us say there are 100 fruits & 10 among them are oranges and you are building a model to detect Oranges.
If the Model1 detects 12 fruits as oranges rest as non-oranges, but only 8 of them are oranges.
* Precision = 8/12 = 66%. (only 8 were actually oranges out of the 12 orange detections)
* Recall = 8/10 = 80%. Only 8 among the 10 oranges are detected accurately
Assignment: if another model say Model2 using which 15 fruits are detected as oranges, and all the 10 oranges are detected
Then what is Precision & Recall. Calculate and to check the answer at the bottom of the page.
- Precision: Measures the proportion of true positive detections among all detections.
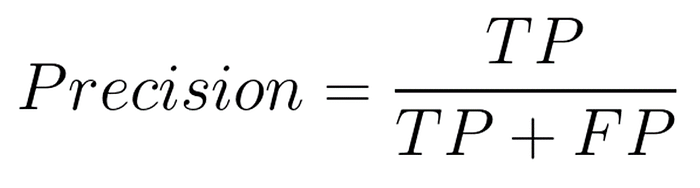
- Recall: Measures the proportion of true positive detections out of all actual objects.

- F1 Score: The harmonic mean of precision and recall, offering a single metric that balances both.
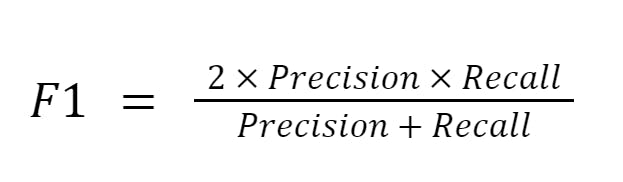
Higher precision indicates fewer false positives, while higher recall indicates fewer false negatives. The F1 score provides an overall measure of accuracy.
¶ 8. Mean Average Precision (mAP)
Mean Average Precision (mAP) is the most commonly used metric for evaluating object detection models. It calculates the average precision across all classes and IoU thresholds to provide a single score representing model performance.
The mAP formula can be expressed as:

where k is the number of classes, and APi is the average precision for class i.
The mAP metric provides an overall assessment of how well a model detects objects across multiple classes and thresholds, making it a standard for comparing model performance.
¶ 9. Feature Maps and Convolutions
In object detection, a feature map is a processed image representation that highlights important features for detecting objects. Feature maps are produced by convolutional layers in neural networks:
- Convolutional Layers: Extract features such as edges, textures, and shapes through filters that slide across the image.
- Strided Convolutions: Reduces spatial dimensions in feature maps, retaining only critical details.
- Multi-Scale Feature Maps: Modern architectures use feature maps of multiple scales to detect objects of different sizes in the same image.
Feature maps allow a model to represent and understand objects at different levels of detail.
¶ Top Performing Models in this Field
Numerous models have been developed for object detection, each offering a unique approach to balancing speed and accuracy. Here are three of the most widely used models:
¶ 1. YOLO (You Only Look Once)
- Overview: YOLO is a real-time object detection system that views the entire image only once, breaking it down into a grid and predicting bounding boxes and class probabilities for each cell in a single forward pass.
- Key Advantage: High-speed processing, making it ideal for real-time applications.
- Limitations: Tends to struggle with small objects due to its grid-based prediction system, which can miss objects that do not align with grid cells.
¶ 2. RCNN (Regions with CNN)
- Overview: RCNN family of models (RCNN, Fast RCNN, Faster RCNN) adopts a two-stage approach. In the first stage, it identifies regions of interest (RoIs), and in the second stage, it classifies and refines bounding boxes within each region.
- Key Advantage: High accuracy, as it combines region proposals with deep feature extraction.
- Limitations: Slower than single-stage models like YOLO due to the multiple stages of computation, making it less suitable for real-time detection.
¶ 3. SSD (Single Shot MultiBox Detector)
- Overview: SSD performs object detection in a single stage by using anchor boxes of multiple sizes and aspect ratios to detect objects of different scales within a single pass.
- Key Advantage: Fast and effective at handling objects of varying sizes without sacrificing accuracy.
- Limitations: Can be less accurate on smaller objects compared to two-stage models like Faster RCNN.
Each of these models offers different strengths, and selecting the right one depends on the application's specific requirements in terms of speed and accuracy.
¶ Use Cases
Let's explore some real-world use cases where object detection is making a significant impact:
- Surveillance: Detecting intruders, weapons, or other threats in real time, improving the safety of public spaces.
- Autonomous Vehicles: Recognizing objects like pedestrians, cars, or road signs to assist with navigation and safety.
- Healthcare: Identifying abnormalities in medical scans, supporting faster and more accurate diagnoses.
- Agriculture: Monitoring crops, livestock, and pests, allowing for timely interventions and resource optimization.

In each case, object detection models allow for automation and enhance decision-making by providing real-time insights.
¶ Quiz answers
Model2 : ( Precision = 66%, Recall = 100% )
¶ Navigation
Main Page | Next Section (Environment Setup)